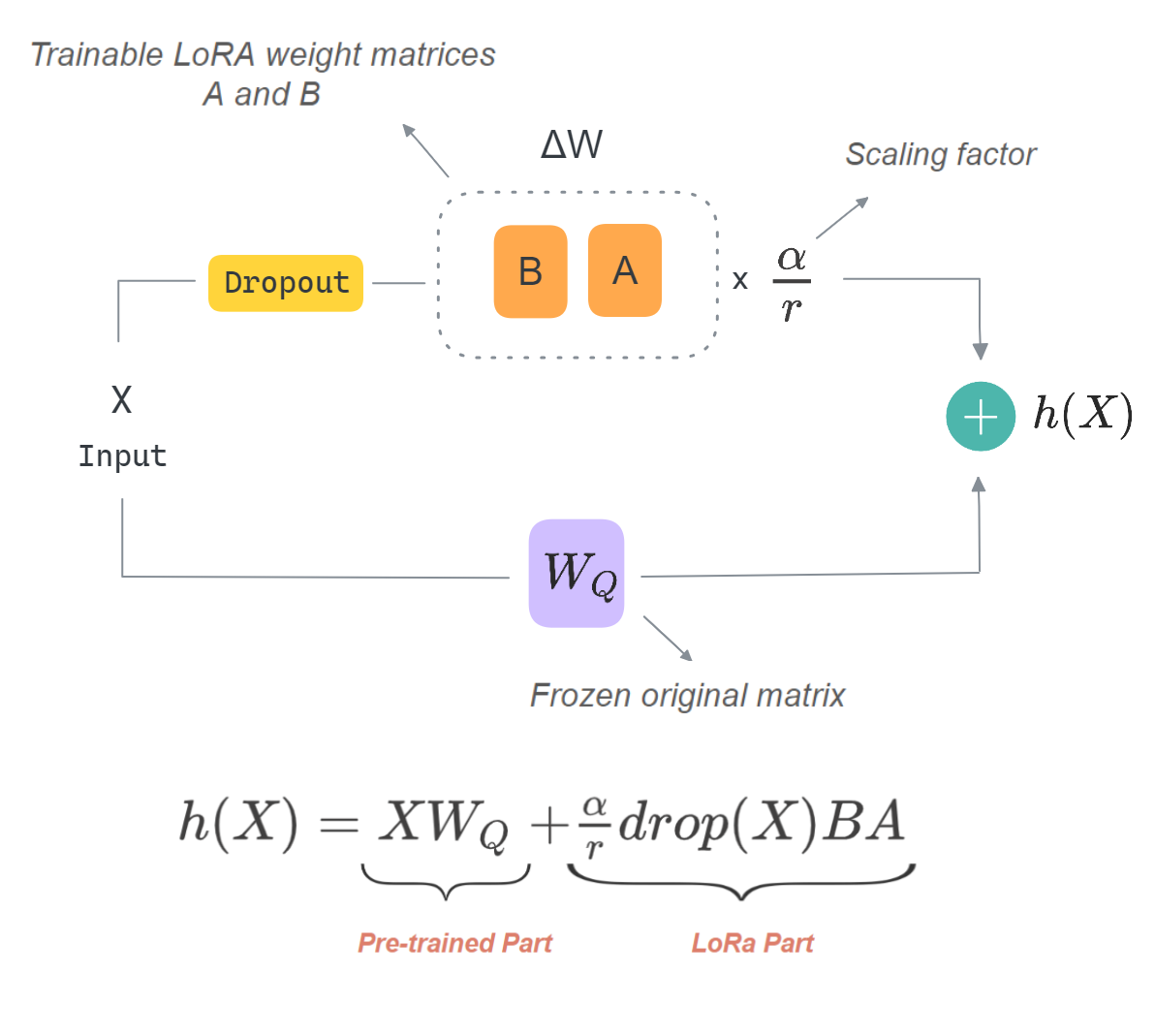
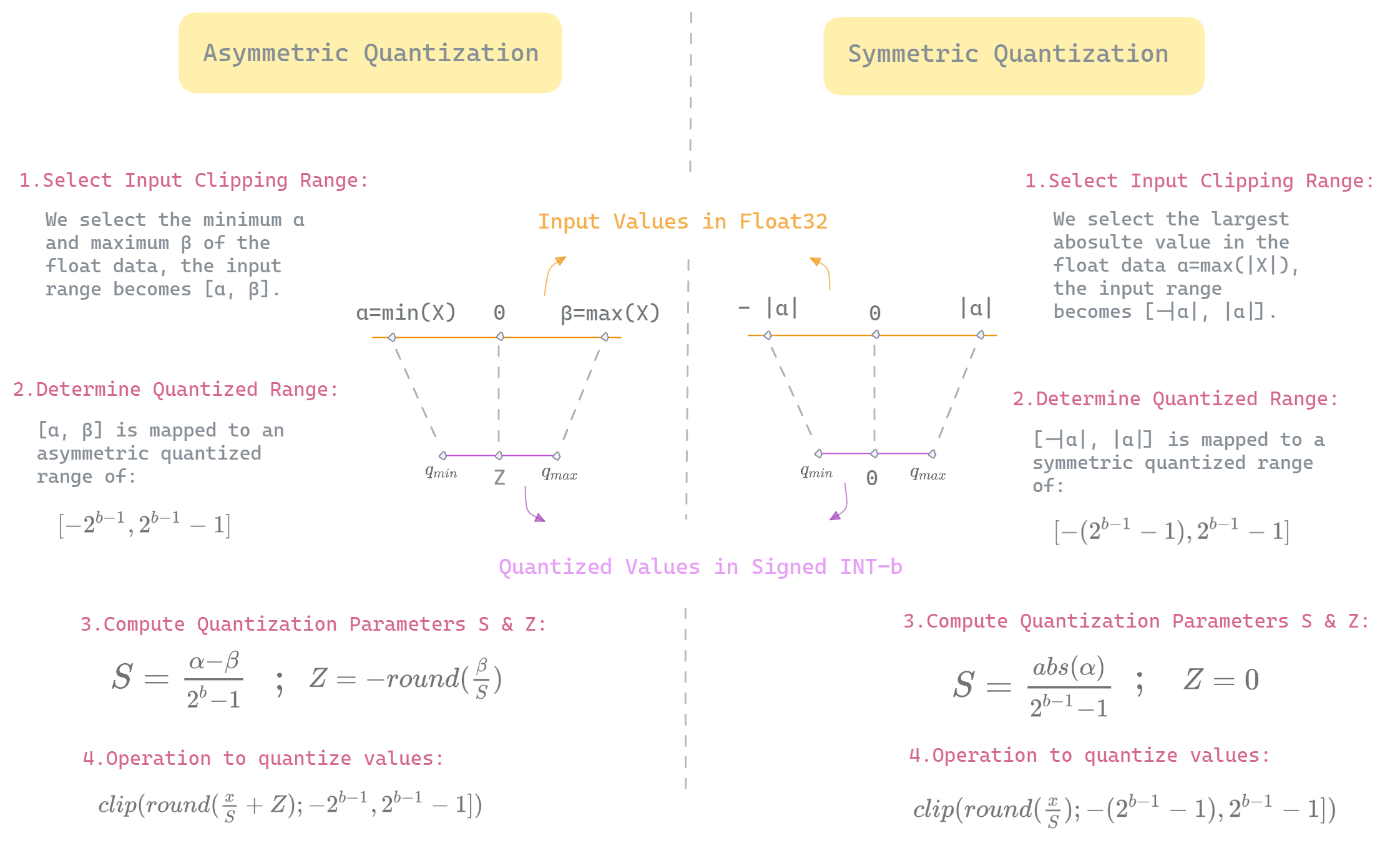
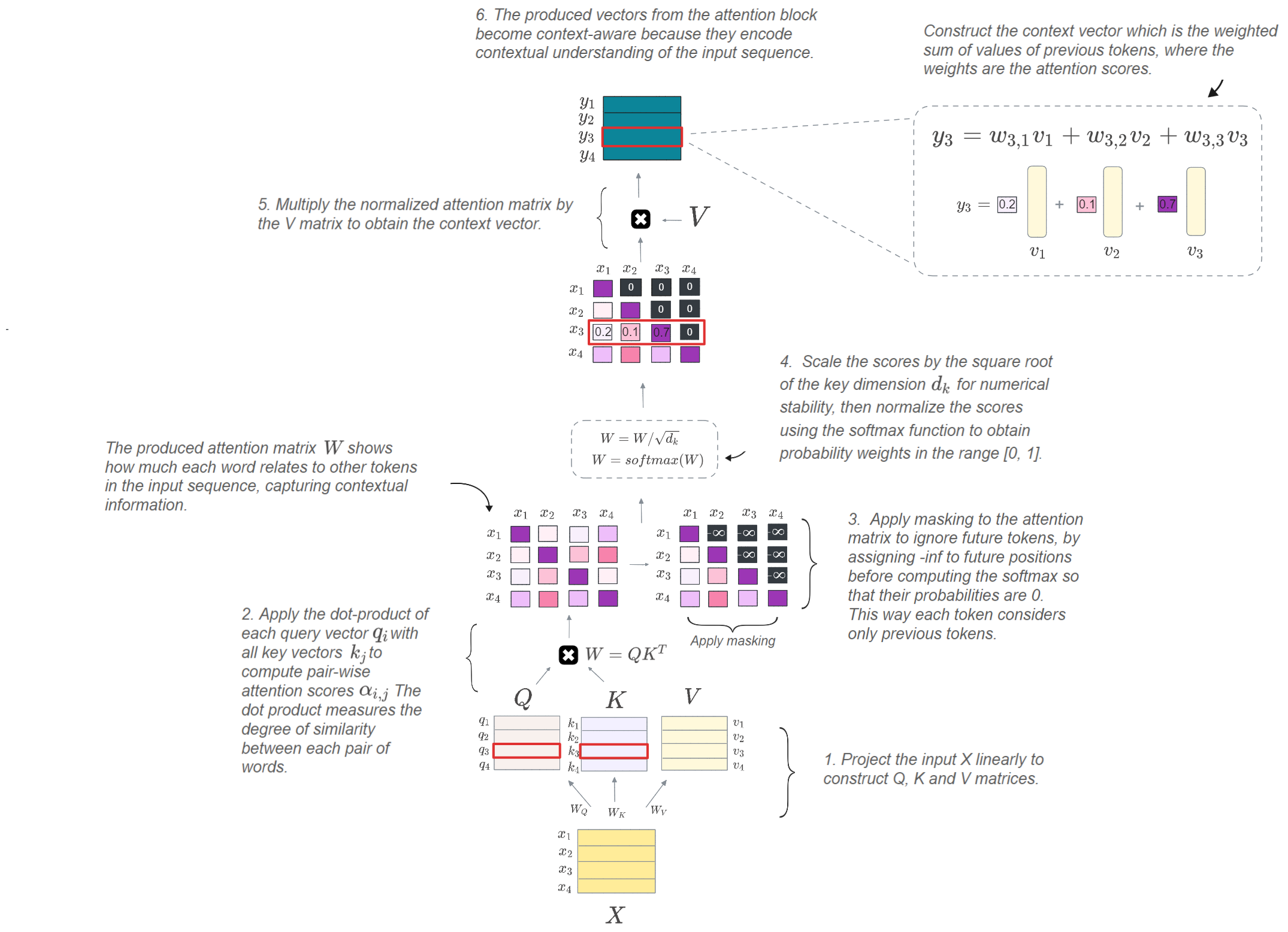
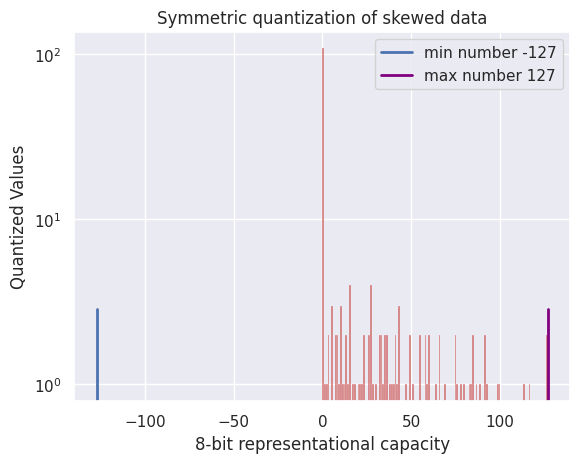
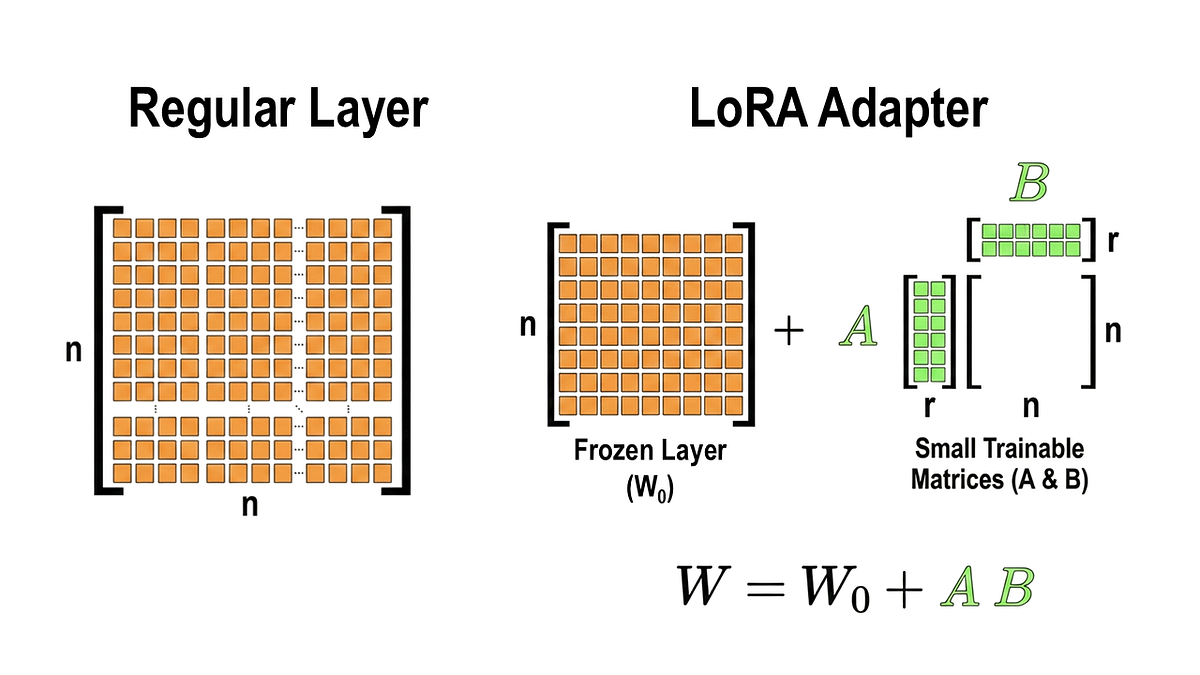
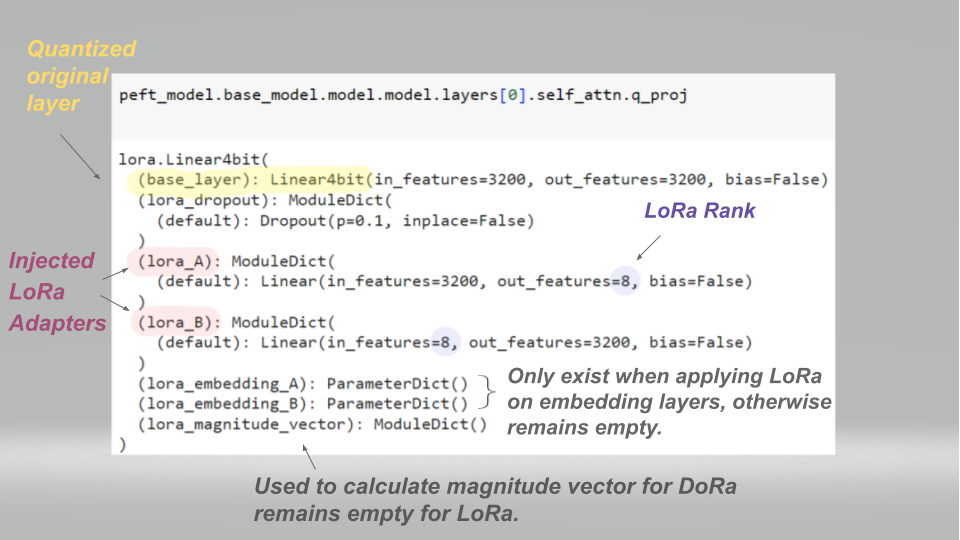
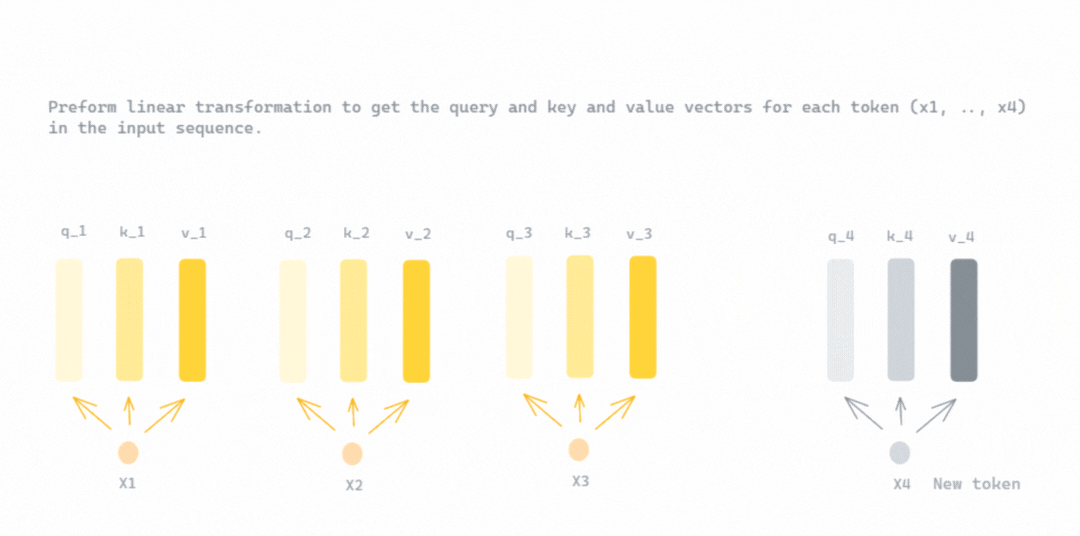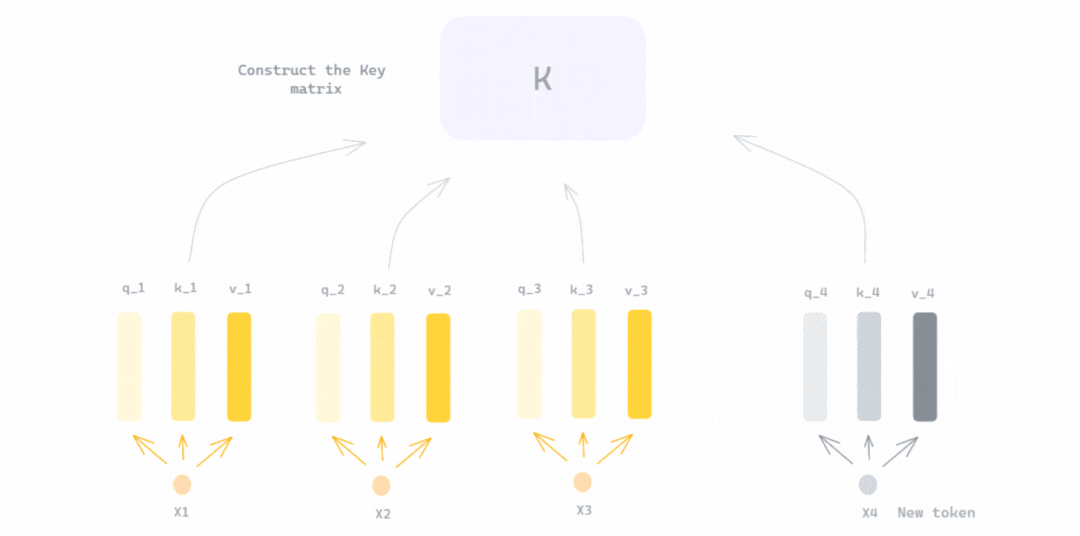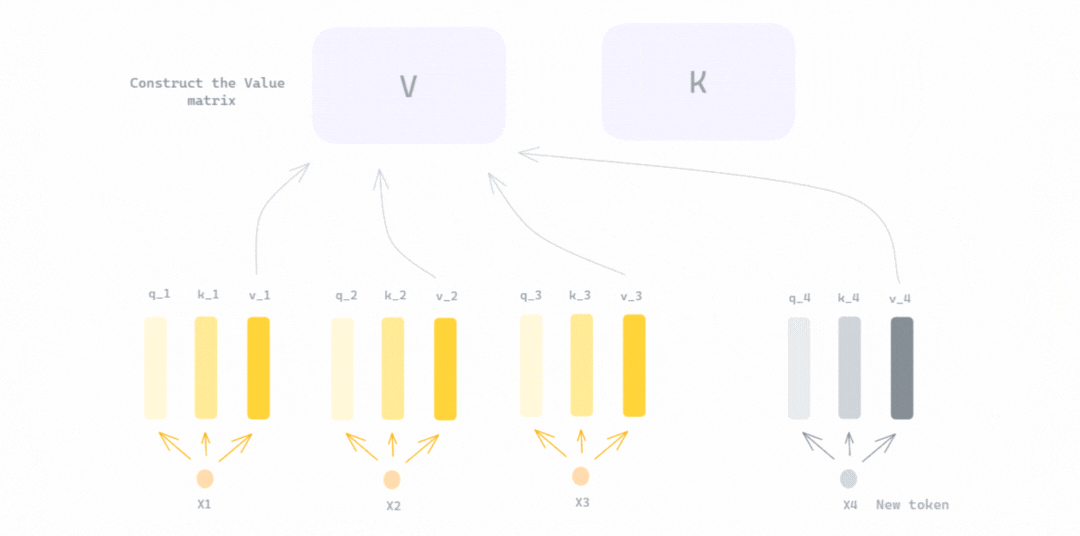
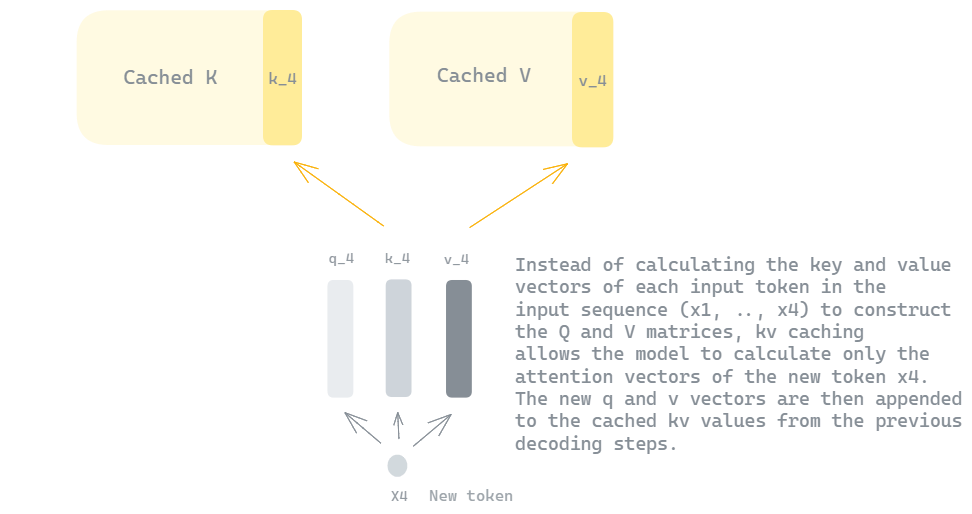
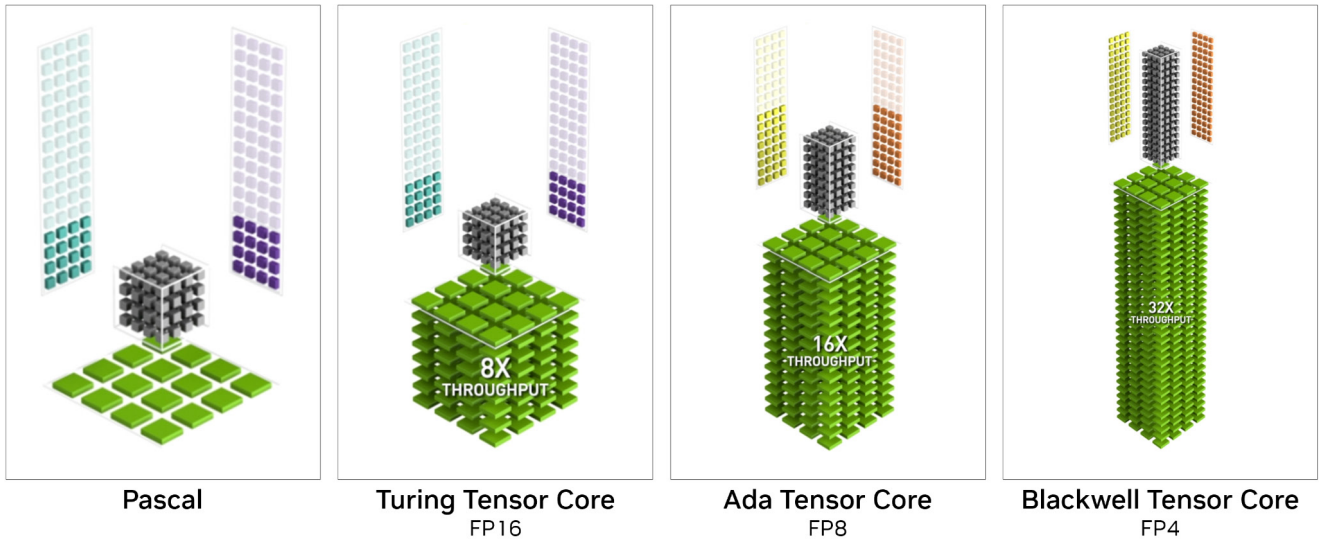
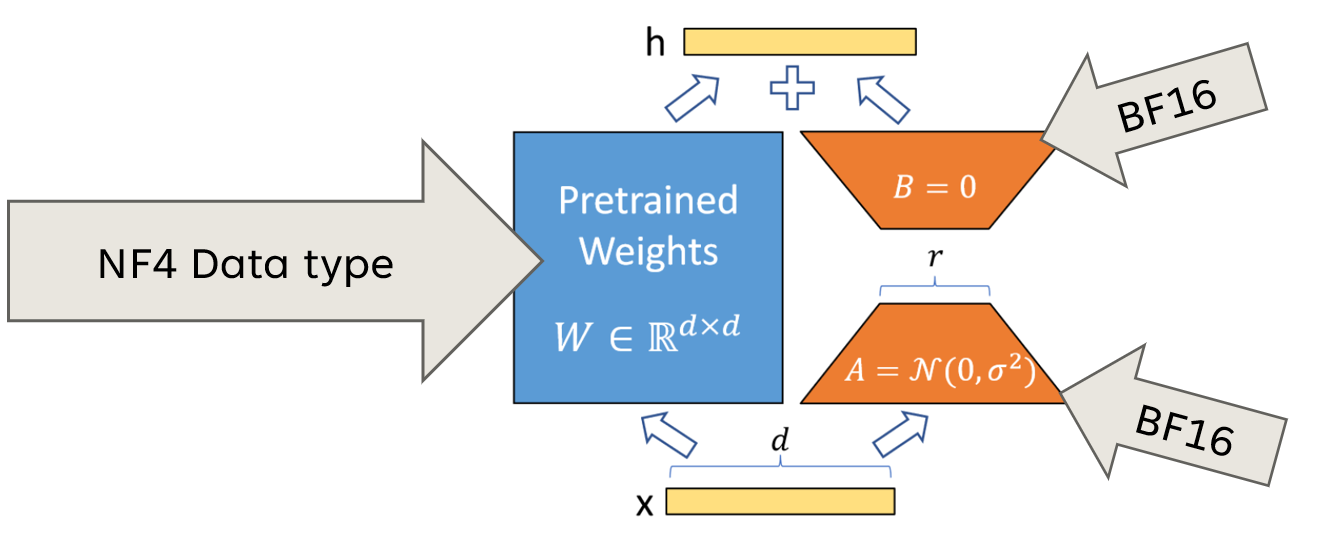
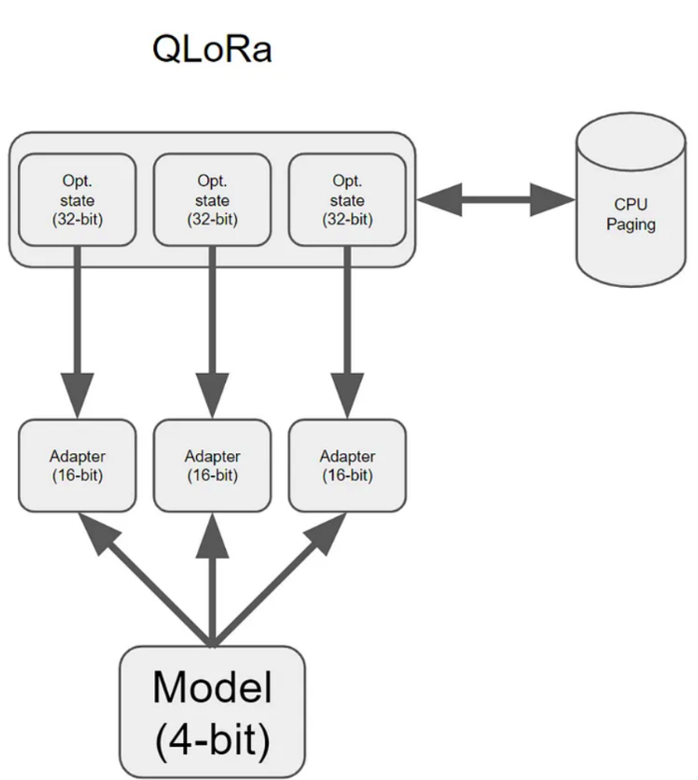
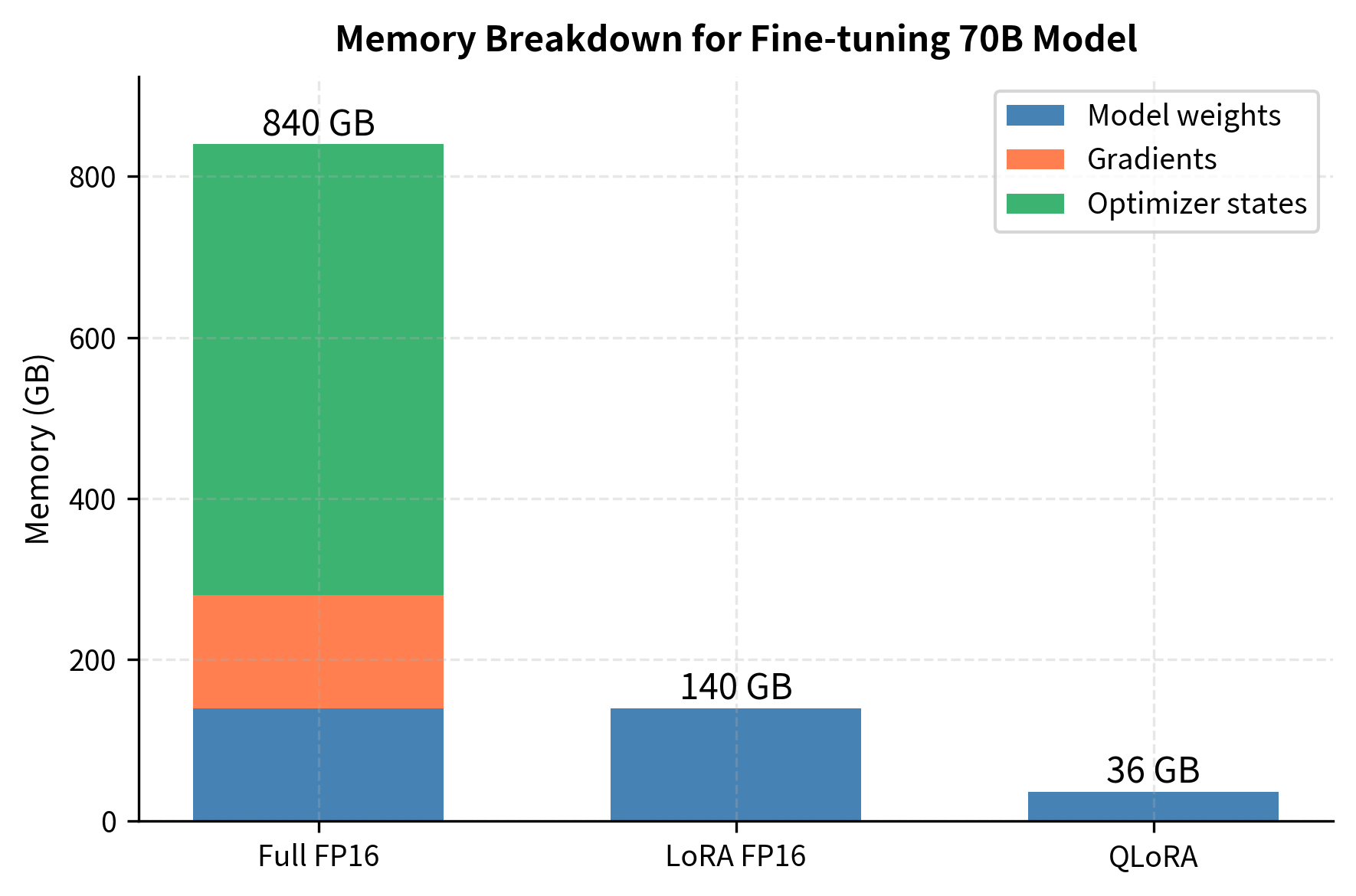
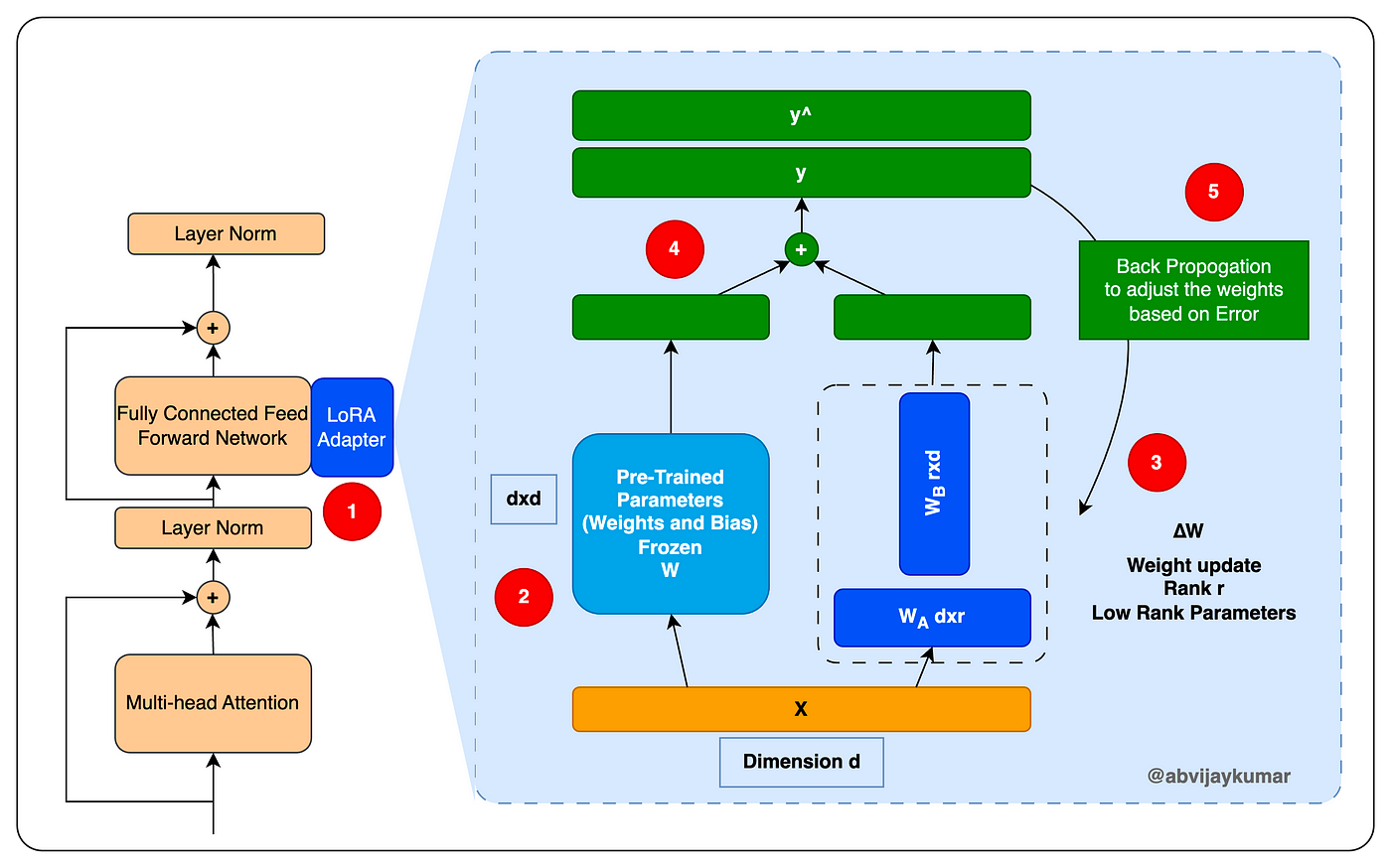
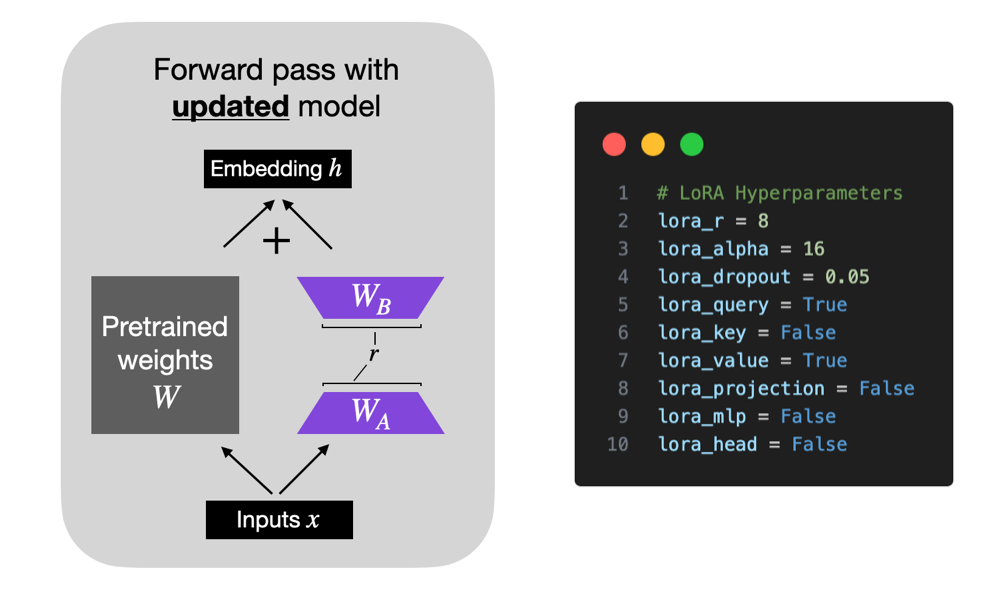
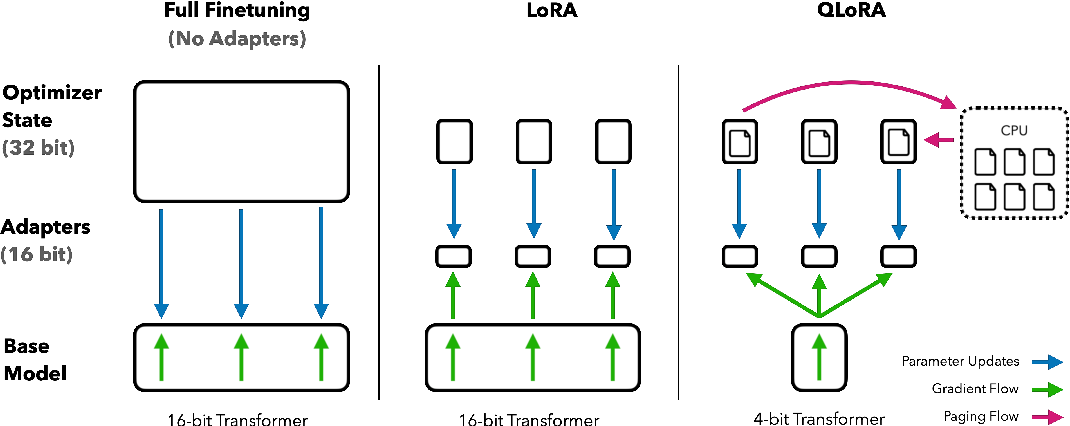
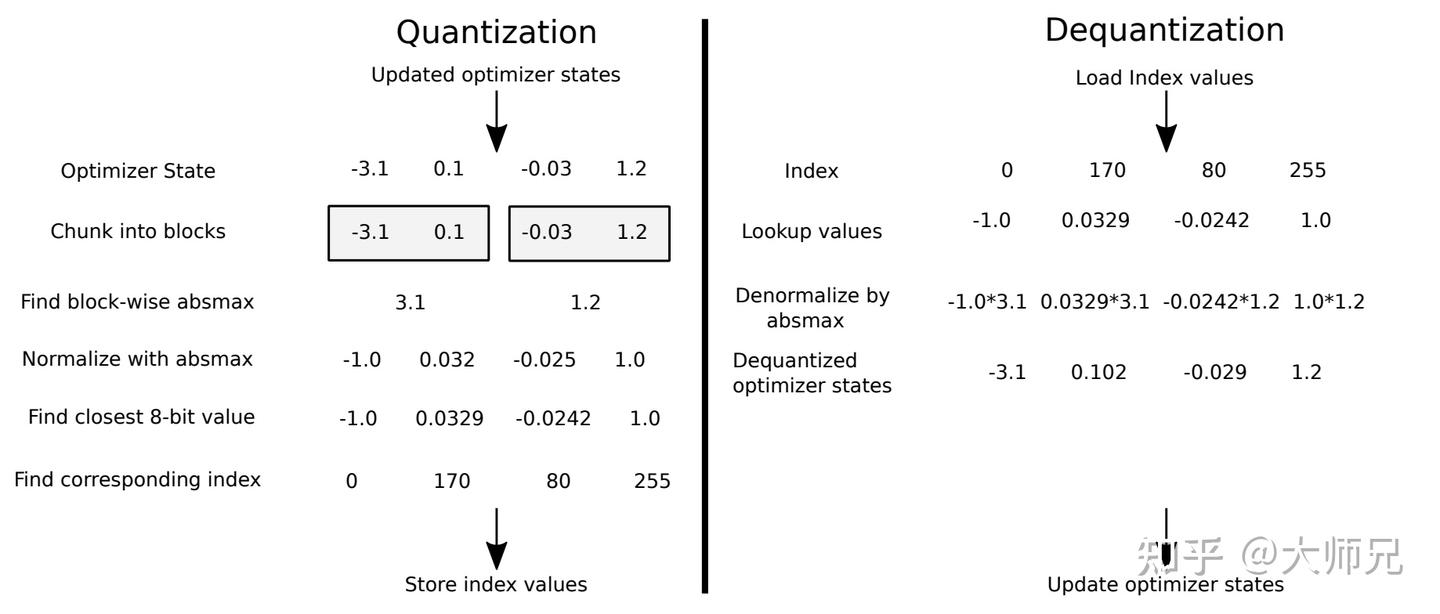
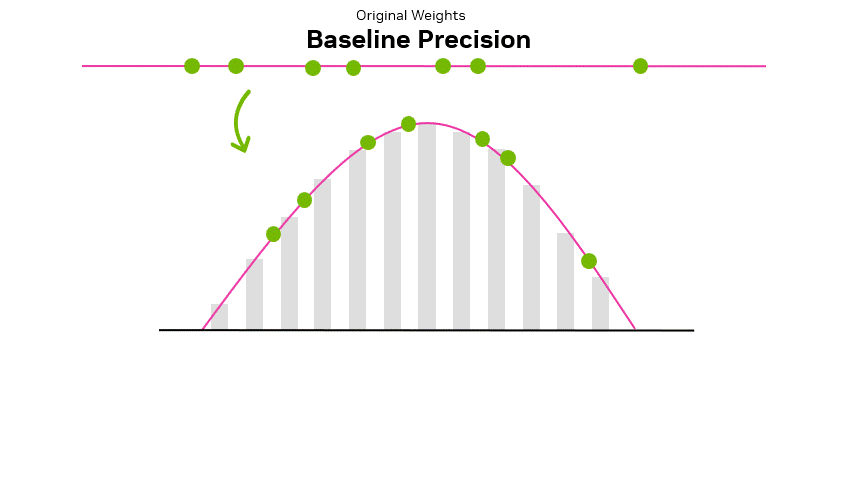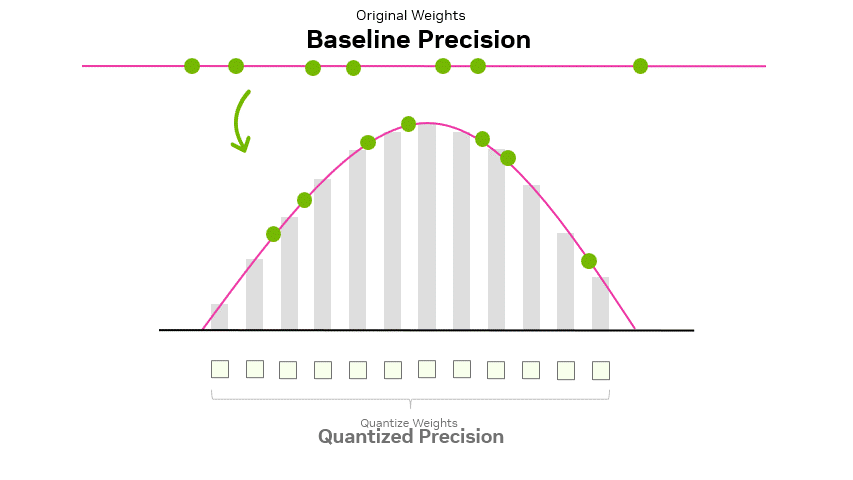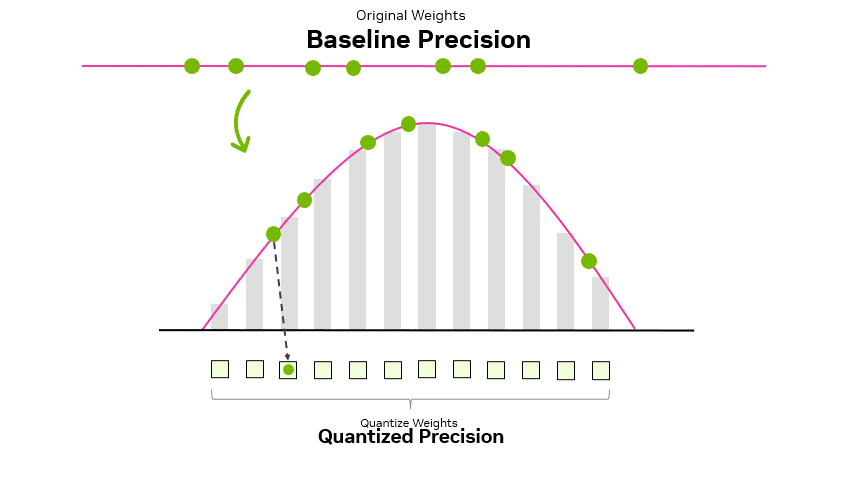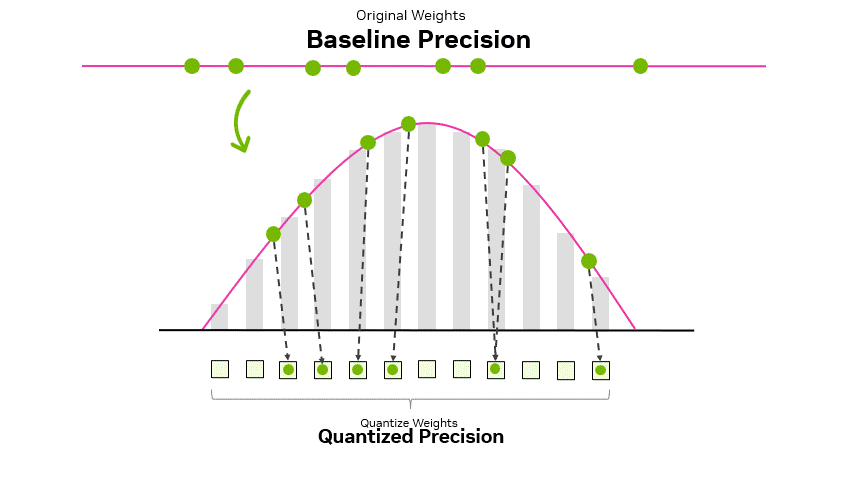
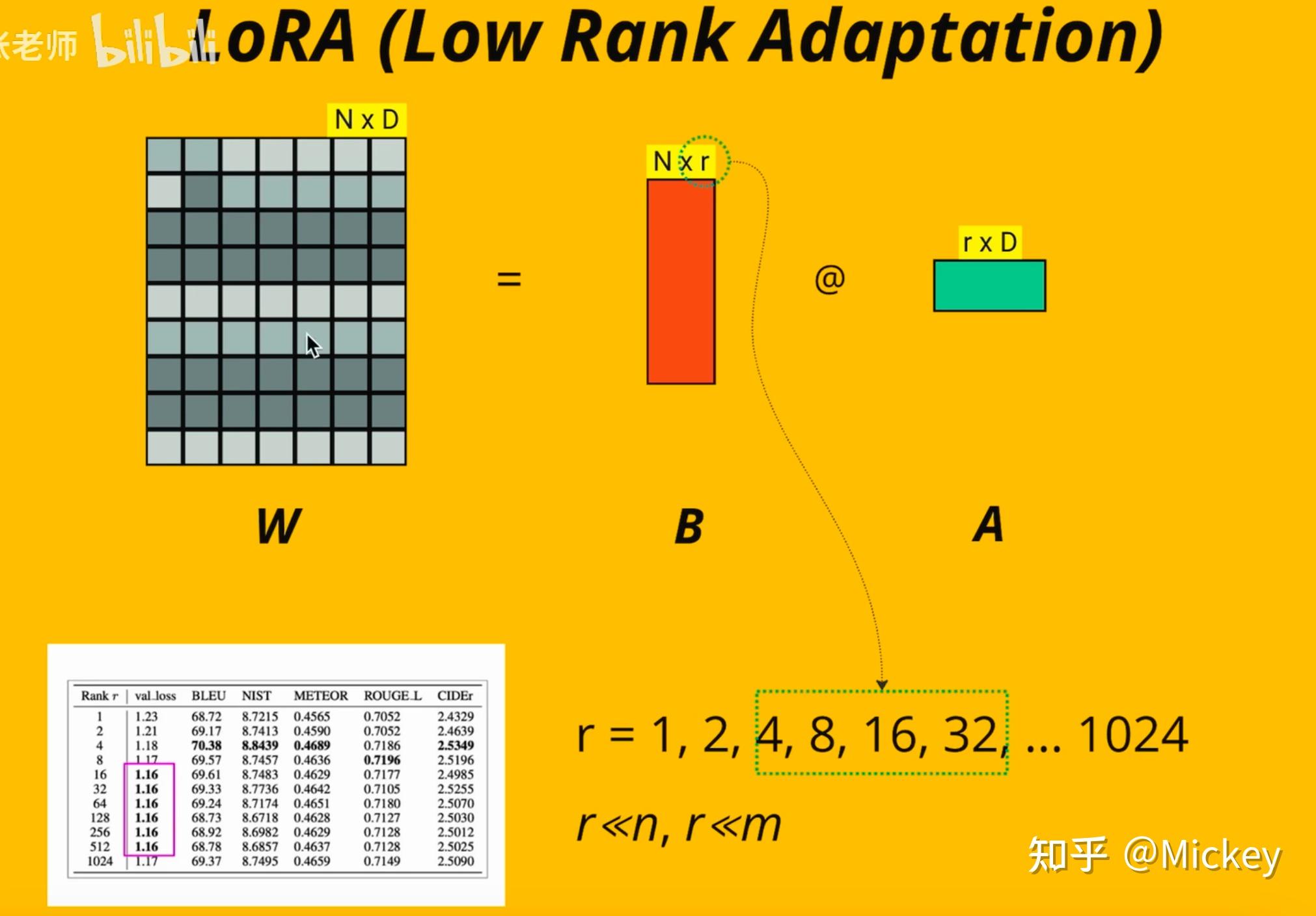
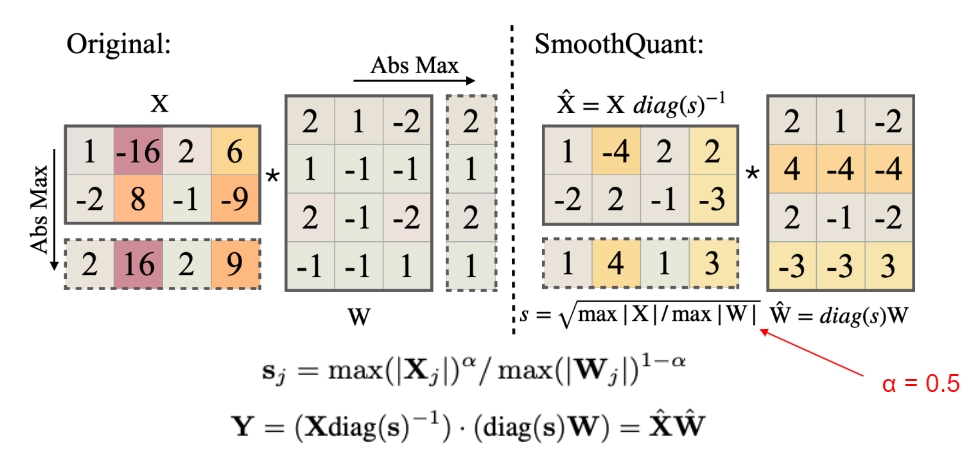
Showing 120 of 120on this page. Filters & sort apply to loaded results; URL updates for sharing.120 of 120 on this page
Building Efficient Fine-tuning with LoRA, QLoRA and Quantization from ...
Mastering QLoRa : A Deep Dive into 4-Bit Quantization and LoRa ...
QLoRA 4-bit quantization · ggml-org llama.cpp · Discussion #1595 · GitHub
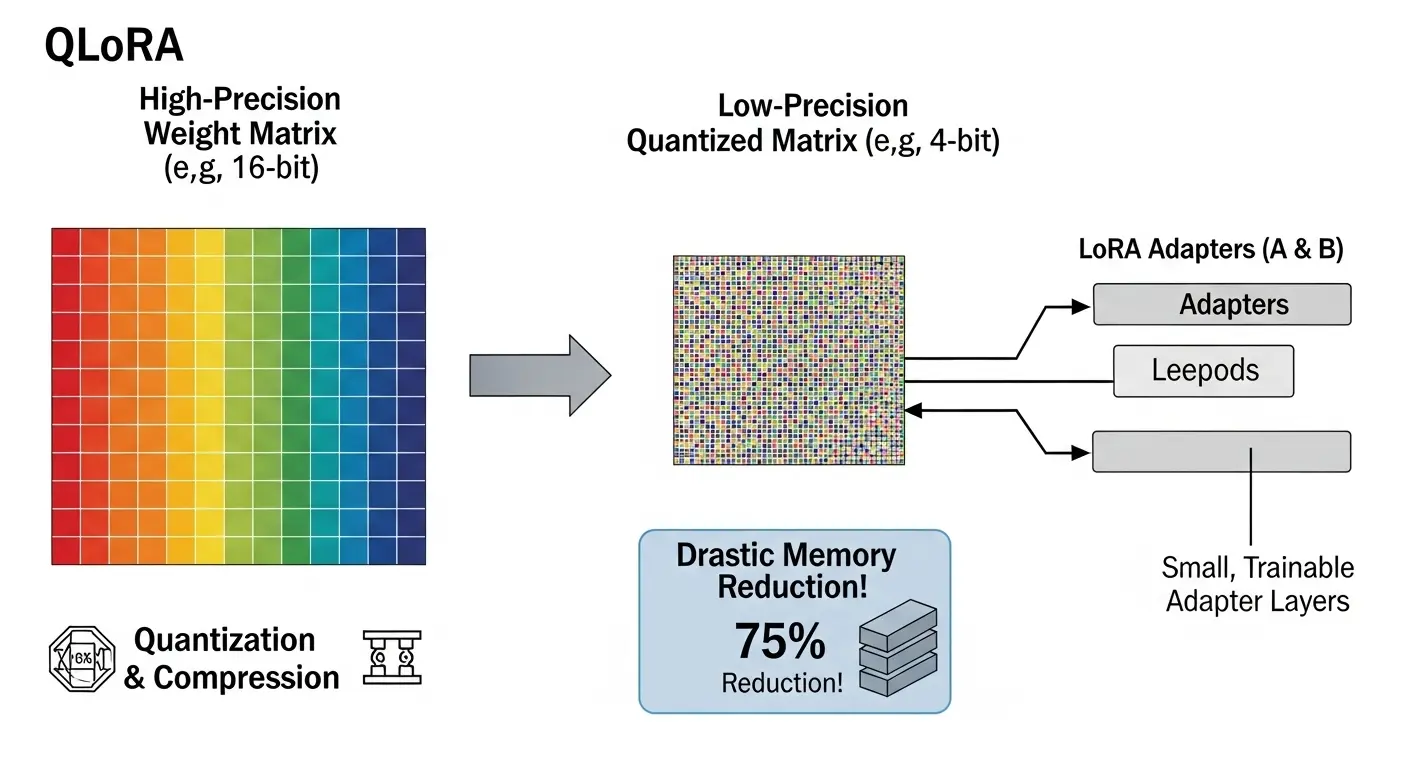
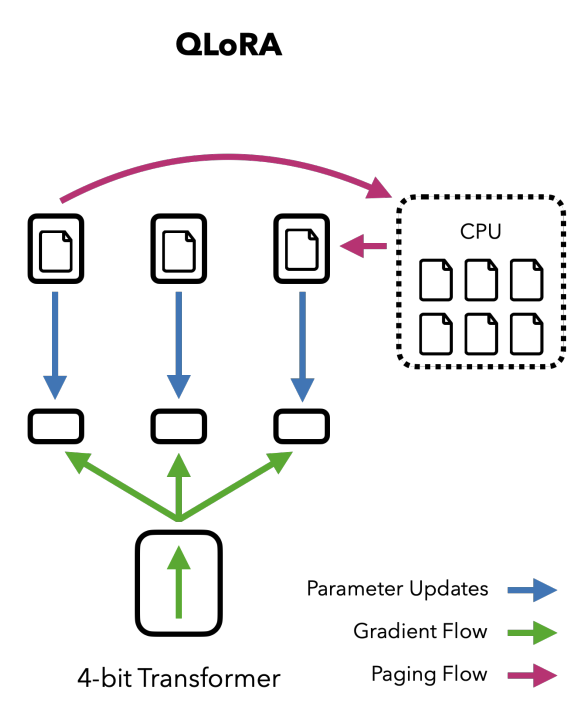
Quantization and QLoRA Explained
QLoRA 4 bit quantization - Allows to fine tune LLaMa sized models on ...
Model Optimization is Getting More Accessible: Quantization and QLoRA
Quantization of LLMs and Fine-Tuning with QLoRA
Deep Dive Into Quantization in QLoRA | by Sudo_Write | Medium
Free Video: Understanding 4-bit Quantization and QLoRA - Memory ...
QLoRA Explained - How 4 Bit Quantization Unlocks Frontier Models
Quantization in Fine Tuning LLM With QLoRA - YouTube
NeMo QLoRA Guide — NVIDIA NeMo Framework User Guide
QLoRA — 如何在单个 GPU 上微调 LLM_训练mistral 7b lora 单卡gpu-CSDN博客
Low-Rank Adaptation (LoRA) And Quantization Unlocking AI Efficiency
QLoRA: Quantization for Fine Tuning - YouTube
Quantization + Fine-Tuning: LoRA, QLoRA, and Beyond
Edge 337: Understanding QLoRA - by Jesus Rodriguez
Fine-Tuning Models: A Deep Dive into Quantization, LoRA & QLoRA - DEV ...
QLoRA Fine-Tuning with Unsloth | Medium
GPTQ vs AWQ vs NF4: Choosing the Right LLM Quantization Pipeline
LLM Quantization Explained: Q4 vs Q8 — What's the Difference and Which ...
Understanding QLoRA - Efficient Finetuning of Quantized LLMs
QLoRA (Quantized Low-Rank Adapter)
qlora
Understanding Quantization in AI: A Comprehensive Guide Including LoRA ...
Qlora (Quantized Low Rank Adaptation) significantly enhances compute ...
QLora Explained and Fine tuning on Phi-2 Tutorial (Quantized LORA ...
QLoRA: 4-Bit Quantization for Memory-Efficient LLM Fine-Tuning ...
QLoRA: Key Quantization and Fine-tuning Techniques in the Era of Large ...
In-depth guide to fine-tuning LLMs with LoRA and QLoRA
New LLM-Quantization LoftQ outperforms QLoRA - YouTube
QLoRA Explained: Fine-Tuning Large Language Models
QLoRA - Efficient Finetuning of Quantized LLMs - YouTube
Understanding QLoRA | Di's Blog
How to do LLM fine-tuning: Quantization, LoRA, and QLoRA | Rakesh ...
QLoRA — Train your LLMs on a Single GPU
Understanding QLoRA: Quantized Fine-Tuning | AI Tutorial | Next Electronics
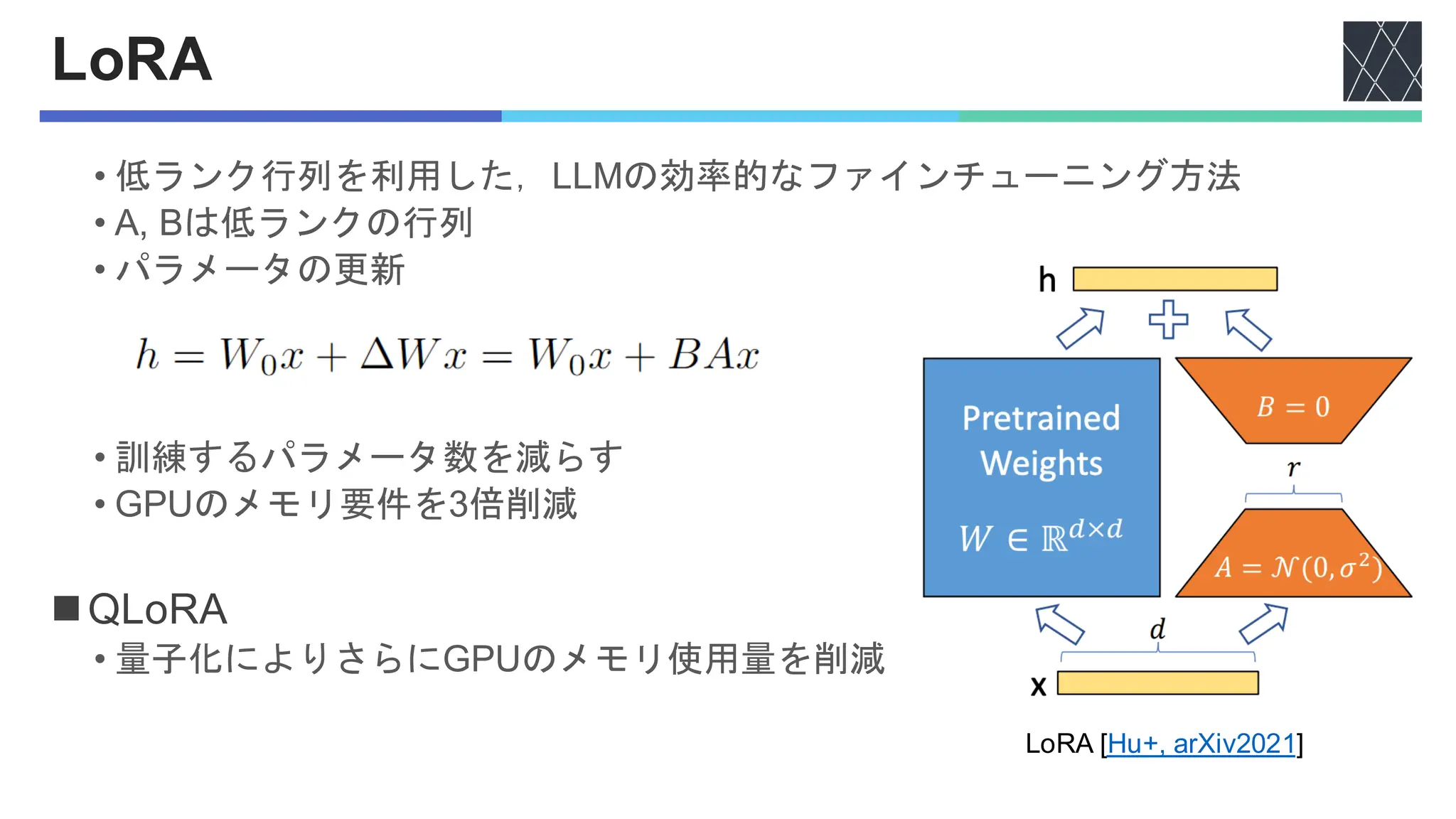
LLMファインチューニング徹底解説: 知識、手法、PyTorch/LoRAによる独自AI構築ガイド
[2502.13167] SmartLLM: Smart Contract Auditing using Custom Generative AI
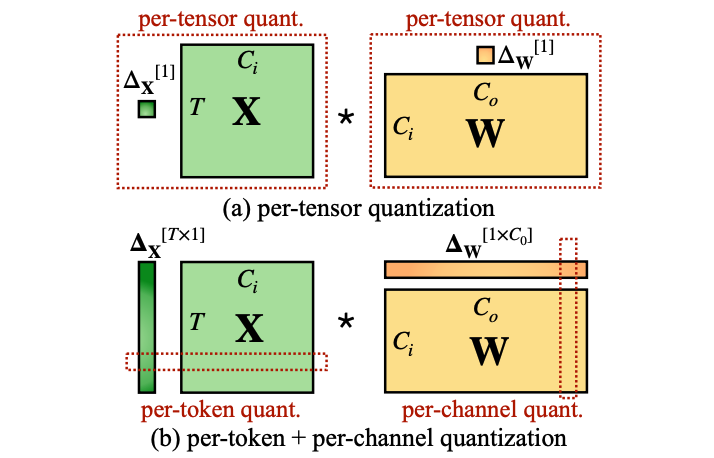
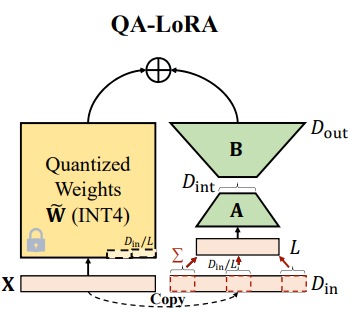
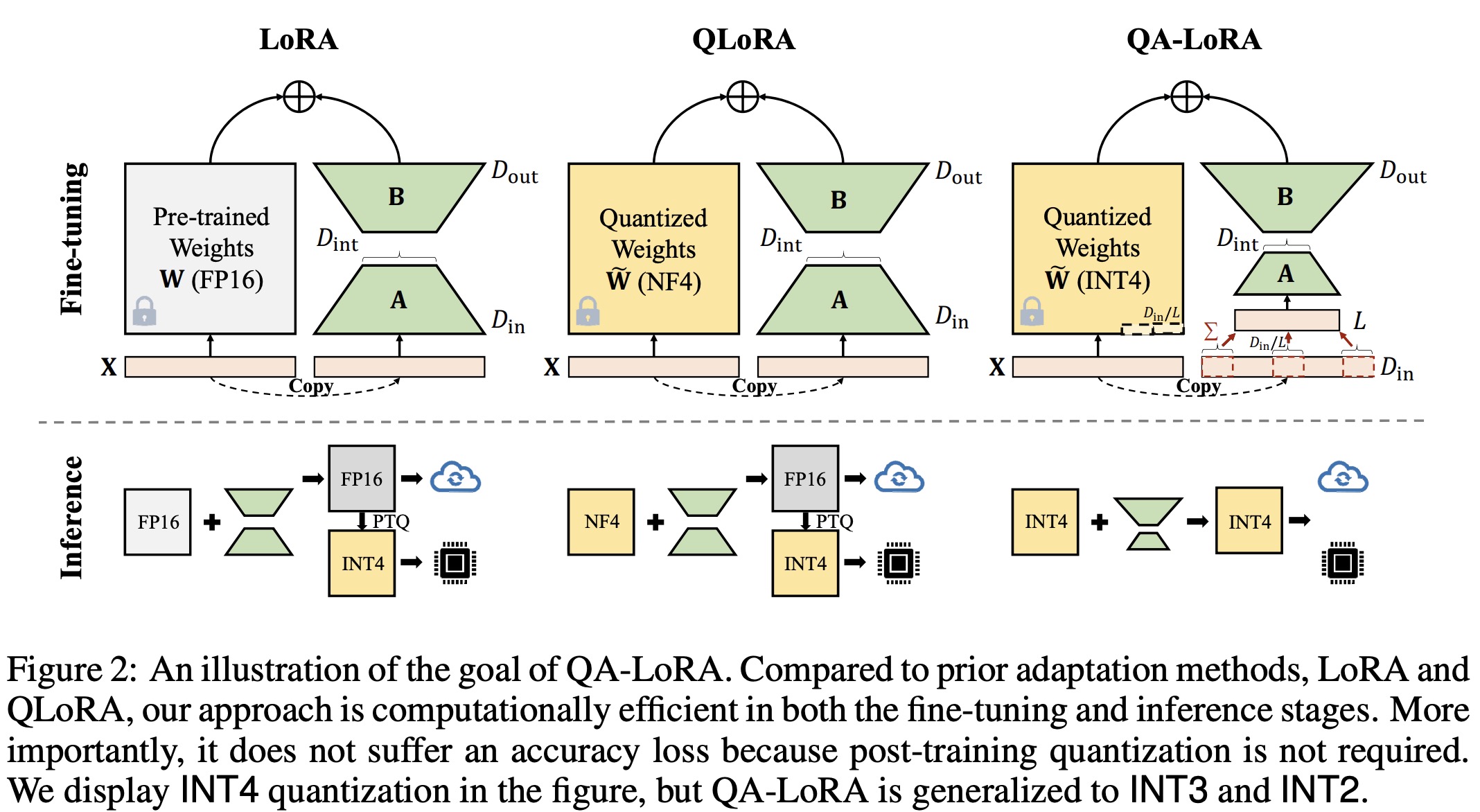
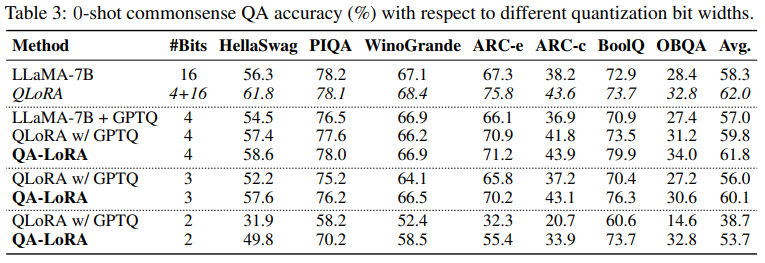
QA-LoRA: Quantization-Aware Fine-tuning for Large Language Models
Paper Review: QA-LoRA: Quantization-Aware Low-Rank Adaptation of Large ...
LLM QLoRA(Quantized Low-Rank Adaptation)详解、代码实现与应用 | AwesomeML
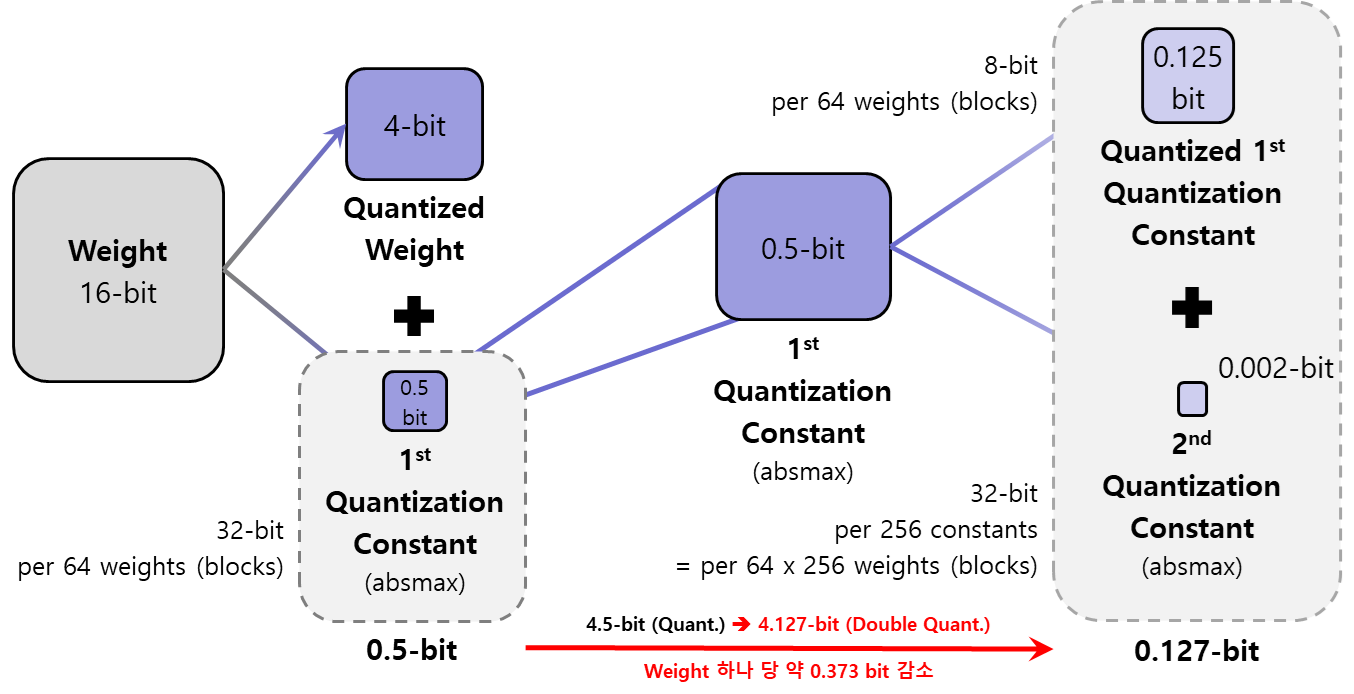
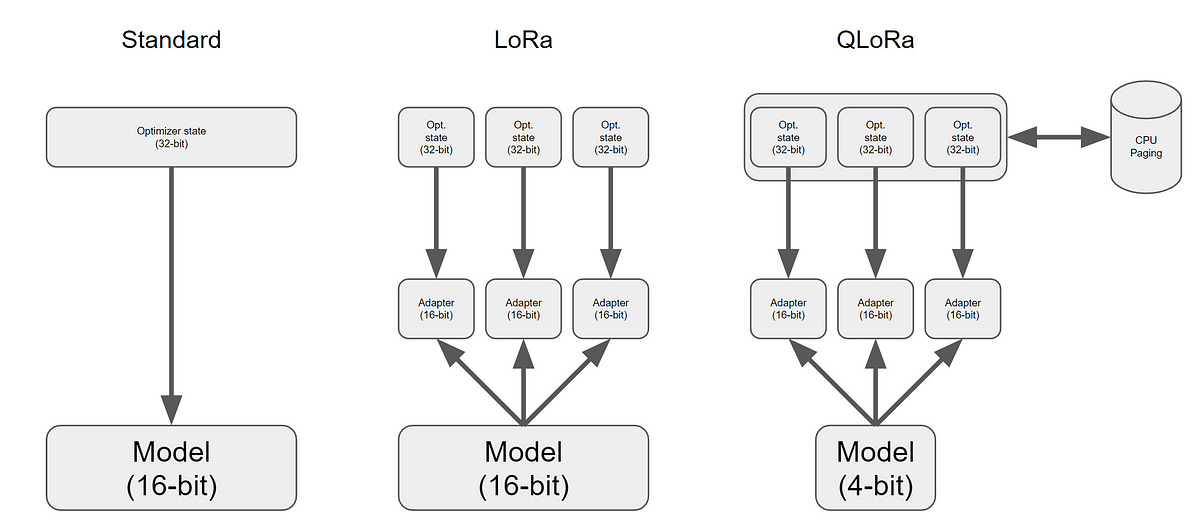
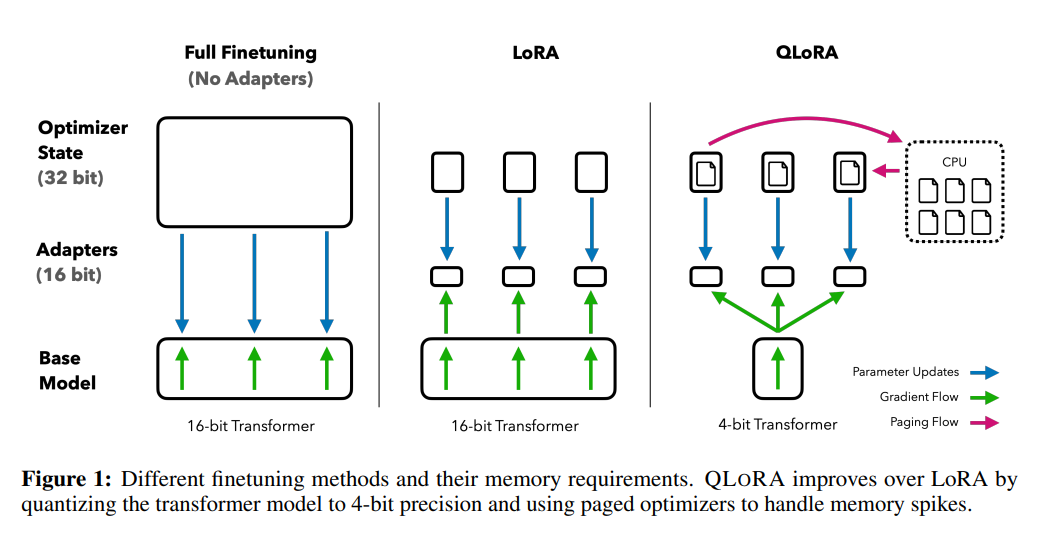
[QLoRA] QLoRA: Efficient Finetuning of Quantized LLMs
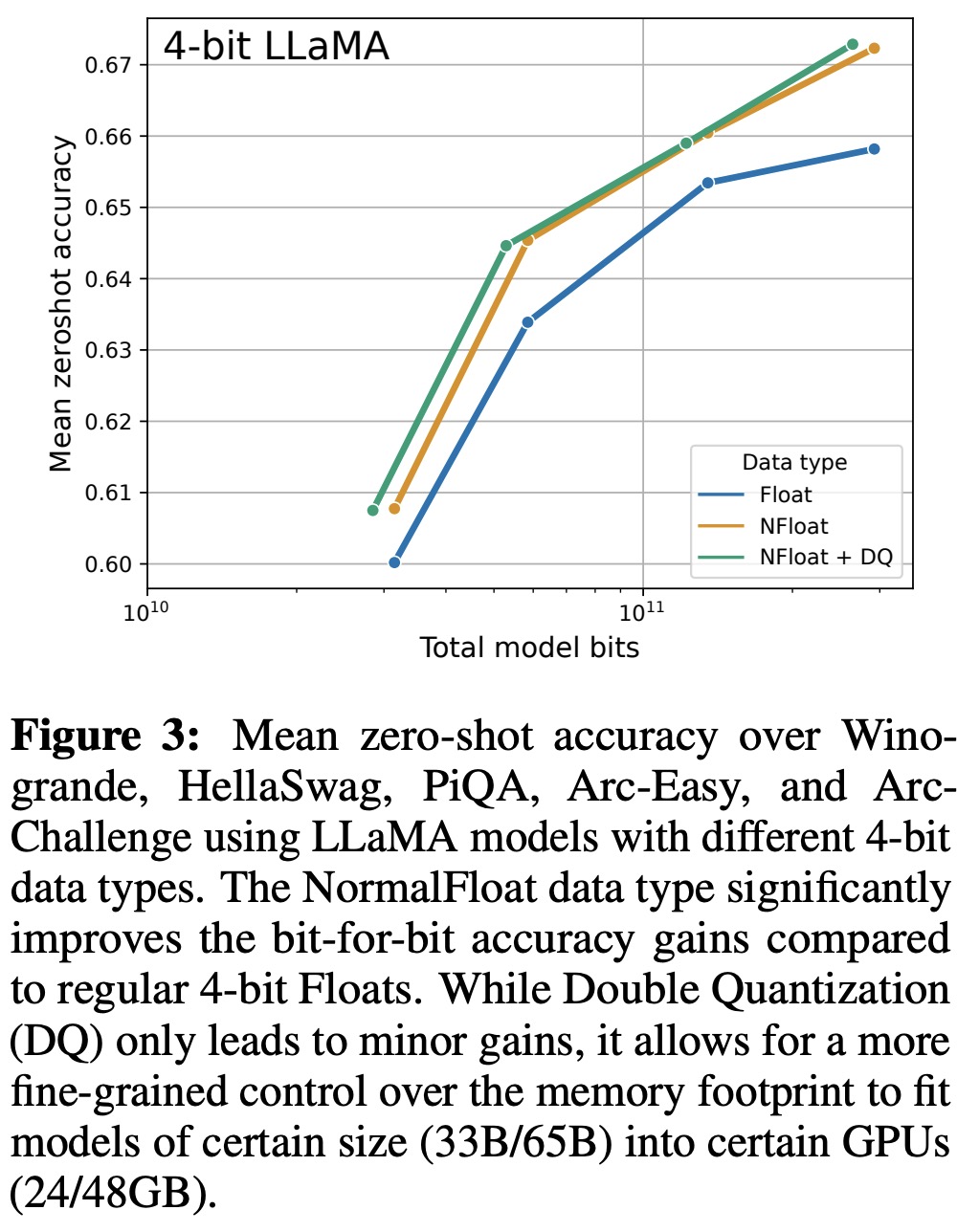
QLoRA: Efficient Finetuning of Quantized LLMs
QLoRA: Efficient Finetuning of Quantized LLMs: Paper and Code - CatalyzeX
QLoRA: Efficient Finetuning of Quantized LLMs - Explained Simply ...
QLoRA(Quantized LoRA)详解 - 知乎
⚡ QLoRA: Efficient Fine-Tuning of Large Language Models with ...
Optimizing LLMs for Performance and Accuracy with Post-Training ...
Quantization-Aware Training (QAT) - The Technology Bringing Powerful AI ...
(PDF) QLoRA: Efficient Finetuning of Quantized LLMs
QLoRA: Efficient Finetuning of Quantized Large Language Models (Tim ...
QLoRA: Quantized Low-Rank Adaptation paper explained | by Astarag ...
论文精读:QLoRA: Efficient Finetuning of Quantized LLMs - 知乎
Quantized LoRA (QLoRA) Explained
75HardResearch Day 13/75: 25 April 2024 | QLoRA: Quantized Low Rank ...
論文紹介:QLoRA: Efficient Finetuning of Quantized LLMs | PDF
Quantized Low-Rank Adaptation ‘QLORA’ - YouTube
QLoRA: Efficient Finetuning of Quantized LLMs - Speaker Deck
QLoRA:Efficient Finetuning of Quantized LLMs - 知乎
LLM Quantization-Build and Optimize AI Models Efficiently
【9】LoRA、QLoRA、模型量化 - 知乎
LoRA、QLoRA - 知乎
QLoRA: Efficient Finetuning of Quantized LLMs (Ko/En Subtitles) - YouTube
QLORA: Efficient Finetuning of Quantized LLMs | Paper summary - YouTube
GitHub - artidoro/qlora: QLoRA: Efficient Finetuning of Quantized LLMs
PITTI - Article - QLoRA: Efficient Finetuning of Quantized LLMs
The Magic Behind QLORA: Efficient Finetuning of Quantized LLMs - YouTube
Paper Review: QLoRA: Efficient Finetuning of Quantized LLMs – Andrey ...
[Daily Paper] 7. QLORA: Efficient Finetuning of Quantized LLMs - 知乎
Quantized Low-Rank Adaptation(QLoRA) Explained - YouTube
QLoRA:4-bit级别的量化+LoRA方法,用3090在DB-GPT上打造基于33B LLM的个人知识库 - 知乎
Unleashing Efficiency with QLoRA: Revolutionizing Large Model Training
How to run performance and scale validation for OpenShift AI | Red Hat ...
模型量化原理与实践 – Robot 9
QLoRAを知らずして量子化ファインチューニングを語るなかれ
[PDF] QLoRA: Efficient Finetuning of Quantized LLMs | Semantic Scholar
[논문 리뷰] QLoRA: Efficient Finetuning of Quantized LLMs
《QLoRA: Efficient Finetuning of Quantized LLMs 》精华摘译 - 知乎